本文介绍 Google 团队在 2024 年 4 月 10 号发布的论文,地址:http://arxiv.org/abs/2404.07143
论文提出了一种 Infini-attention 技术让基于 Transformer 的大型语言模型可以在固定的内存下,具有处理无限长上下文输入的能力。实验证明,与之前的方法相比,该方法在性能、压缩能力和泛化方面都有很大的提升。
从 Transformer-XL 讲起
论文主要是对比 Transformer-XL,所以我们先从它讲起。
由于 attention 平方时间复杂度的限制,如何让 Transformer 处理更长的输入一直是研究热点。传统的基于 Transformer 的模型,输入长度是固定的较小值。在预训练时,需要将语料切分成这样无数个段分别预训练,因此模型能够捕获的最长上下文就是段的大小,不具备长上下文能力。如下图所示,在训练时 Segment 1 和 Segment 2 之间是没有关联的。

Transformer-XL 提出了一种以空间换时间的方案:

每次输入仍然是固定长度的 Segment,但是它会将上一个 Segment 每一层结点的 key 和 value 缓存起来,以供下一个 Segment 来做 attention,每一个 Segment 都能捕获上一个 Segment 的信息,这样就实现了长上下文的建模。缺点也很明显:只往前存储了一个 Segment 的信息,还是存在信息丢失的问题。
这篇论文就用 Infini-attention 与其做了对比,认为最大的优势就是能够拥有完成的历史上下文:

模型结构
下图展示了 Infini-attention 的结构,
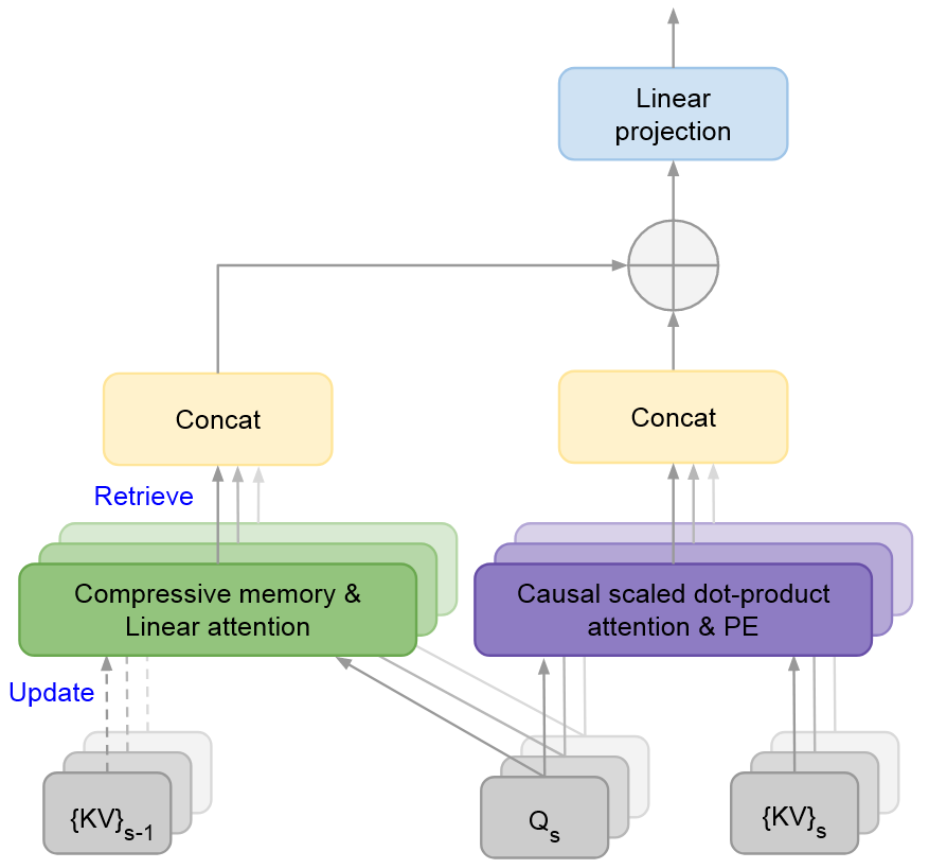
大致思想:设置一个
将检索出来的信息
论文对比了多个长上下文解决方案的空间消耗,支持长度等信息:
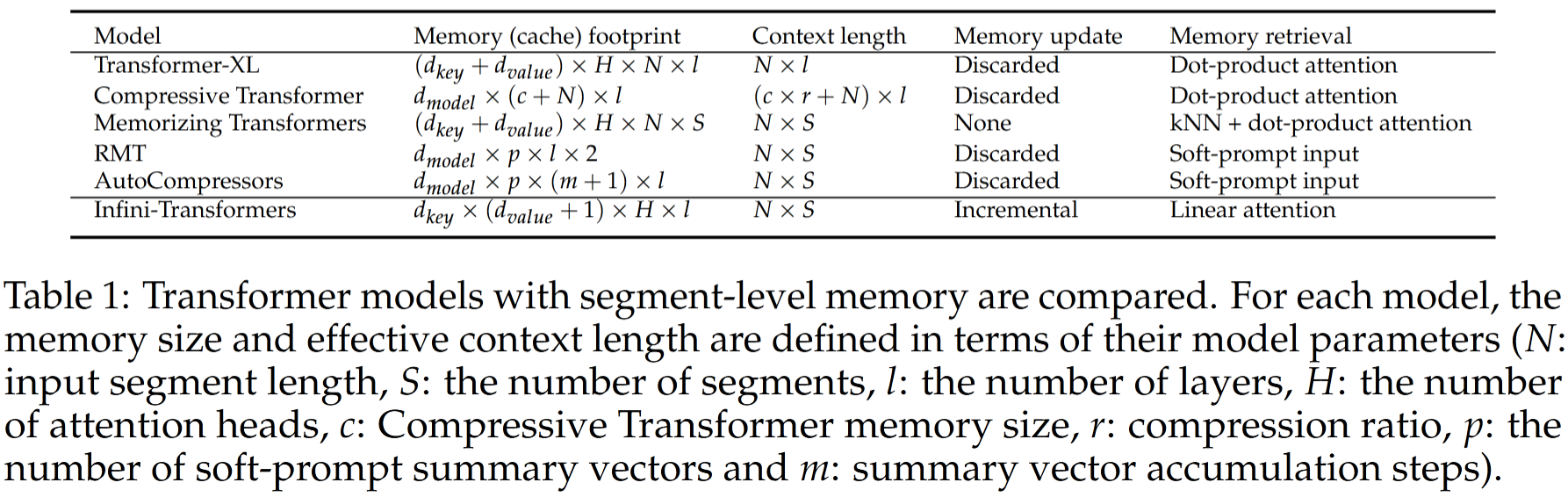
最大的亮点就是 Infini-Transformer 内存占用是一个定值,与输入长度无关。
结果分析
作者在 1M 长上下文检索和 500K 长的书籍摘要中做实验,发现在压缩能力更大的情况下,有了更好的性能:
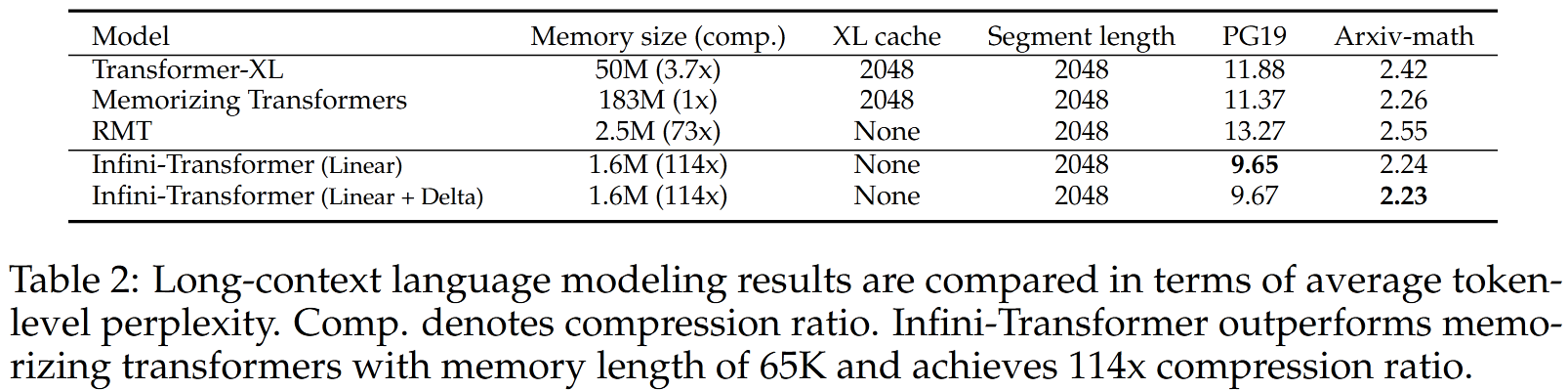
Indini-Transformer 模型在 PG19 和 Arxiv-math 数据集上的表现超越了所有对手,且实现了 114 倍的记忆压缩比。
门控分数分析
前文提到,每一层的每个头都有一个控制当前注意力与上文注意力和权重的参数
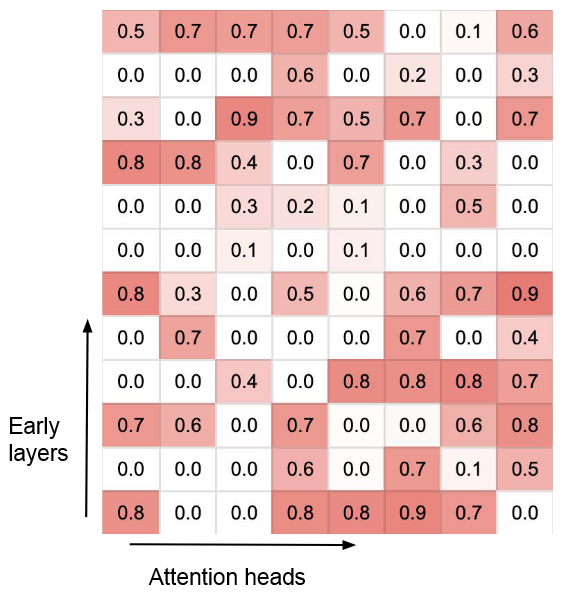
观察到两种类型的门控分数:
- 门控分数接近 0 或 1 的专用头
- 分数接近 0.5 的混合头
专用头用于选择当前输入或上文输入,混合头用于将两者混合,非常有趣!
总结
该工作相当于给模型的每一层加了个 RAG,思想很简单,效果却很好,并且即插即用,可以持续更新知识。期待未来的表现!