Note1- 词法分析
词法分析阶段的任务,简单来说就是从左到右扫描源程序,根据词法规则识别单词,并转换成统一表示的 token 串,它包括:
- 对常数完成数字字符串到数值的转换
- 删掉空格字符和注释
- 检查词法错误,记录行号报错
每个 token 串用一个二元组表示:<种别码/名字,属性值>
正则表达式
我们使用正则语言来表示单词,例如:

而如何识别这些正则表达式呢?我们可以证明任何一个正则表达式都能转化为一个等价的有穷自动机。任何一个正则引擎都会构建相应的有穷自动机进行正则匹配。
有穷自动机
有穷自动机可以分为 DFA 和 NFA


它们之间唯一的区别是状态转移函数不同,对于一个输入,DFA 只能转移到一个确定的状态,而 NFA 却可能转移到多个状态。
还有 ε-NFA,它指输入可以为空的 NFA。
NFA 和 ε-NFA 比 DFA 更容易书写更直观,似乎表达能力更强。但实际上,我们能证明这三者是等价的,即任何一个 NFA 或 ε-NFA 都有一个 DFA 与之等价。
从 NFA 到 DFA
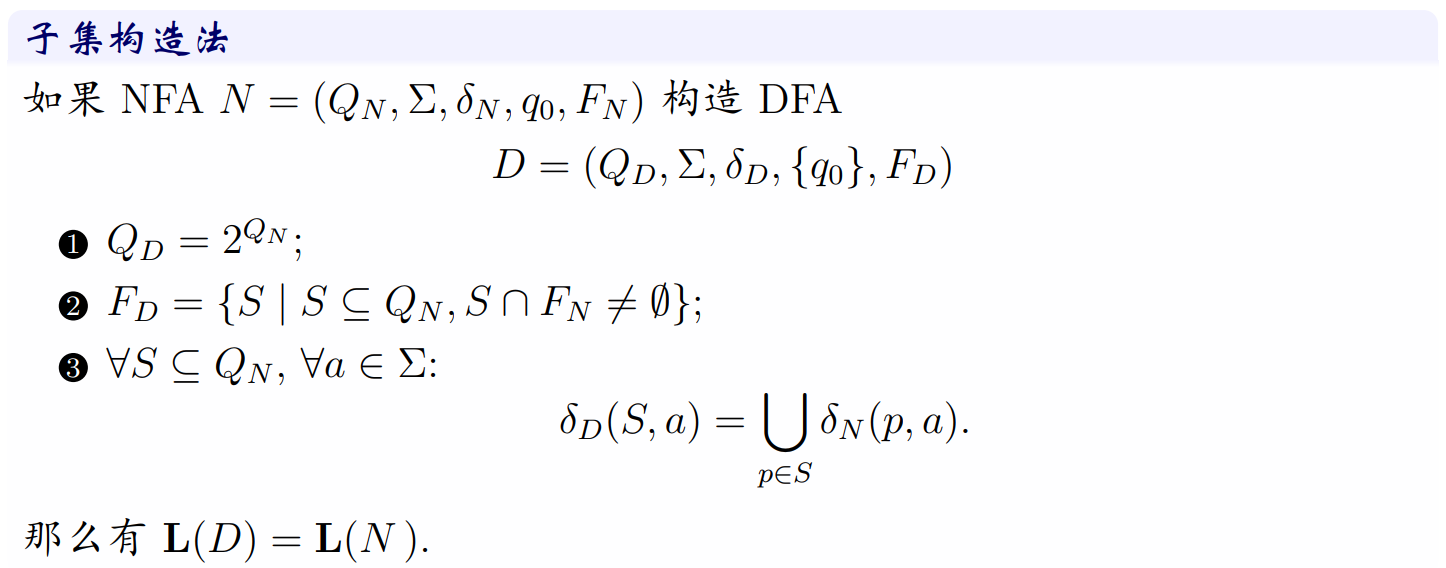
简单来说,就是构造一个 DFA,它的状态集是这个 NFA 状态集的所有子集,当前子集的状态转移函数的输出是该子集所有元素在原 NFA 中输出的并集(也称为闭包)
例如:

从正则表达式到 NFA
从正则表达式到 DFA 要比从 DFA 到正则表达式简单得多。幸好,我们只需要实现从正则表达式到 DFA 的转换。只需使用如下规则递推实现即可:


将正则表达式转换为 ε-NFA,再使用子集构造法将 ε-NFA 转换为 DFA 即实现了正则表达式到 DFA 的转换。接下来的任务就是识别 DFA。
识别 DFA
我们很轻易就能实现识别 DFA 的程序。

到此,我们便完成了识别一个单词的全流程:
- 为单词设计正则表达式
- 将正则表达式转换为 DFA
- 编写程序识别 DFA
下面,还需要说明一些细节。
词法分析的具体实现
错误处理
在词法分析阶段,如果当前状态与当前输入符号在转换表对应项中的信息为空,而当前状态又不是终止状态,则调用错误处理程序,采用错误恢复策略。
Panic Mode(恐慌模式)策略:从剩余的输入中不断删除字符,直到词法分析器能够在剩余输入的开头发现一个正确的字符为止。
生成工具 Lex
在实际实现词法分析过程中,将正则表达式转换为 DFA 的过程完全是一个苦力活,没必要自己实现,已经有现成的轮子来解决这个问题,那便是 Lex。我们只需要设计词法规则(正则表达式),就可以让 Lex 自动生成词法分析器。
Lex 的基本工作原理为:由正则定义生成 NFA,将 NFA 变换成 DFA,DFA 经化简后,模拟生成词法分析器。