Note2- 语法分析
词法分析是以字符为单位,通过正则语言构造出一串 token 序列;而语法分析是以 token 为单位,通过上下文无关文法构造语法分析树。
自顶向下分析
自从向下即从文法开始符号
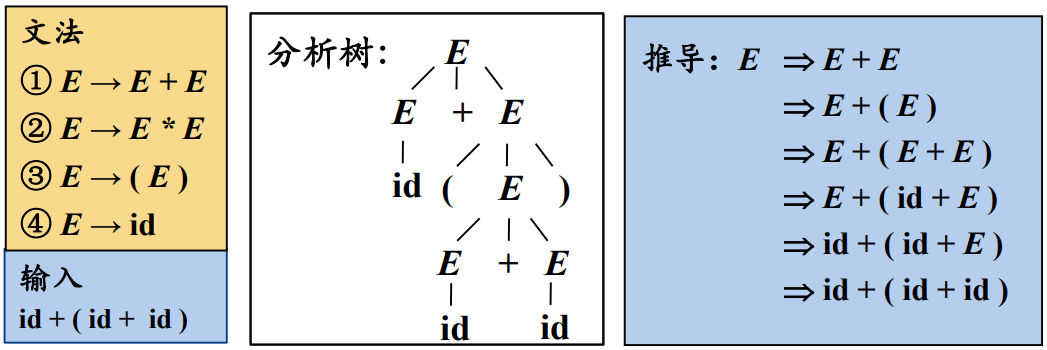
走一遍过程,可以看出,自顶向下分析的核心是两个问题:
- 替换当前句型中的哪个非终结符
- 用该非终结符的哪个候选式进行替换
本小节的核心就是解决这两个问题。对于第一个问题,我们采用最左推导方式,即总是选择每个句型的最左非终结符进行替换。
为了解决第二个问题,我们先要对上下文无关文法进行三种改造。
消除二义性
二义性是指

在第一步推导时,无论是选择

消除直接左递归
左递归可以分为两种:
- 直接左递归。含有
形式产生式的文法 - 间接左递归。含有
形式产生式的文法
它会引起什么问题呢?

于是,就需要消除左递归:


提取左公因子
如果一个非终结符的多个候选存在共同前缀,很容易造成回溯现象:

算法如下:

这是自顶向下语法分析的通用形式,也成为递归下降分析:
-
由一组过程组成,每个过程对应文法的一个非终结符
-
从文法开始符号
对应的过程开始,其中递归调用文法中其它非终结符对应的过程。如果 对应的过程体恰好扫描了整个输入串,则成功完成语法分析

这个过程是很有可能需要回溯的,效率较低。于是就有了预测分析技术,它通过在输入中看
即仅通过当前句型的最左非终结符
先介绍两种简单的
文法。要求每个产生式的右部都以终结符开始,且同一非终结符的各个候选式的首终结符都不同,右部不能包含 产生式。 文法。每个产生式的右部或为 ,或以终结符开始,具有相同左部的产生式又不相交的 SELECT 集
如何判断任意一个文法是不是
FIRST 集
给定一个文法符号串
算法:

FOLLOW 集
可能在某个句型中紧跟在
这个集合主要是用来判断是否使用
算法:

SELECT 集
产生式
例如:
可以用 FOLLOW 集来计算 SELECT 集
- 如果
,则 - 如果
,则
判定条件
文法
等价条件:
( 和 至多有一个能推导出 ) - 如果
,则
构建预测分析表
构造算法:

如果文法
递归的预测分析
递归的预测分析法是指:在递归下降分析中,根据预测分析表进行产生式的选择。
非递归的预测分析
即用下推自动机来模拟,上下文无关文法和下推自动机是等价的。具体过程:
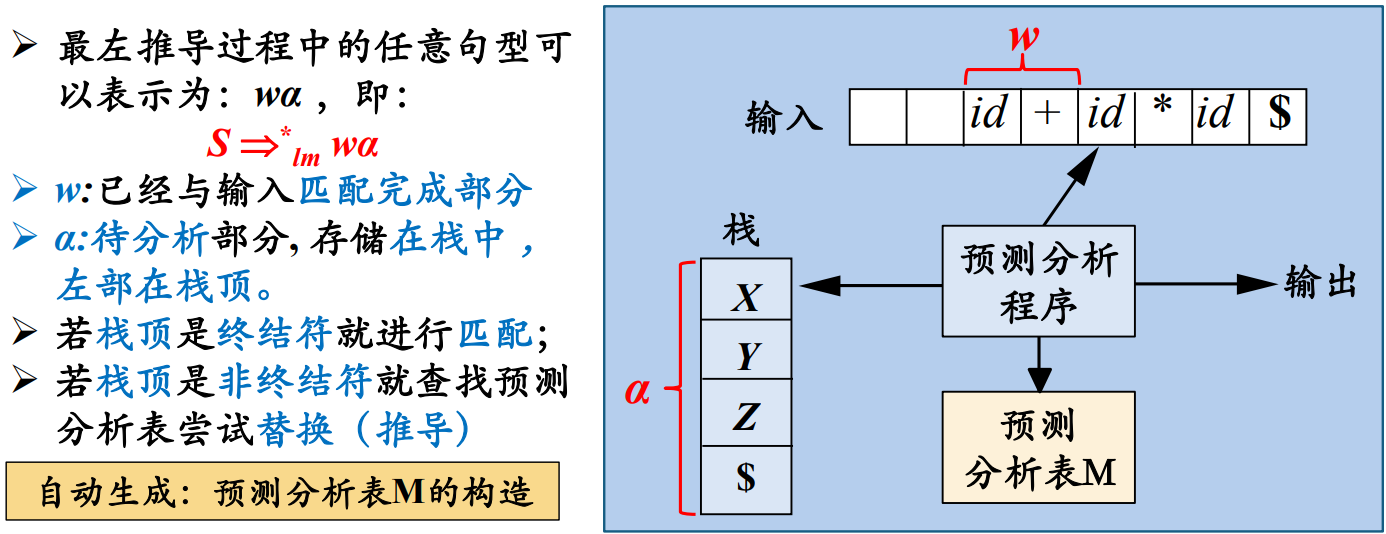
举例:
预测分析法总结
基本步骤
综上,预测分析法的实现步骤为:
- 改造文法:消除二义性、消除左递归、提取左公因子
- 判断是否
文法:具有相同左部的产生式的 SELECT 集互不相交。 - 求每个非终结符的 FIRST 集和 FOLLOW 集
- 求每个候选式的 FIRST 集
- 求具有相同左部产生式的 SELECT 集
- 若是
文法,构造预测析表,实现预测分析器。 - 若不是
文法, 说明文法的复杂性超过预测分析法的分析能力。 - 如果能处理冲突表项,依然可以采用预测分析法。
- 无法处理冲突,采用自底向上分析方法。
错误处理
两种情况下可以检测到语法错误
- 栈顶的终结符和当前输入符号不匹配
- 栈顶非终结符
与当前输入符号 在预测分析表对应项中的信息为空
Panic Mode 策略:
- 如果终结符在栈顶而不能匹配,弹出此终结符
- 如果
为空,则忽略输入中的一些符号,直至遇到同步符号 (synchronizing token)。 - 可以把
中符号设置为同步符号,遇到 中的符号,将 弹出(放弃对 的推导分析),继续分析。 - 可以把
中的符号设置为同步符号,遇到 中的符号时,继续分析。 - 可以把较高层构造的开始符号设置为较低层构造对应非终结符的同步符号,遇到这些符号时,将
弹出,继续分析。
- 可以把
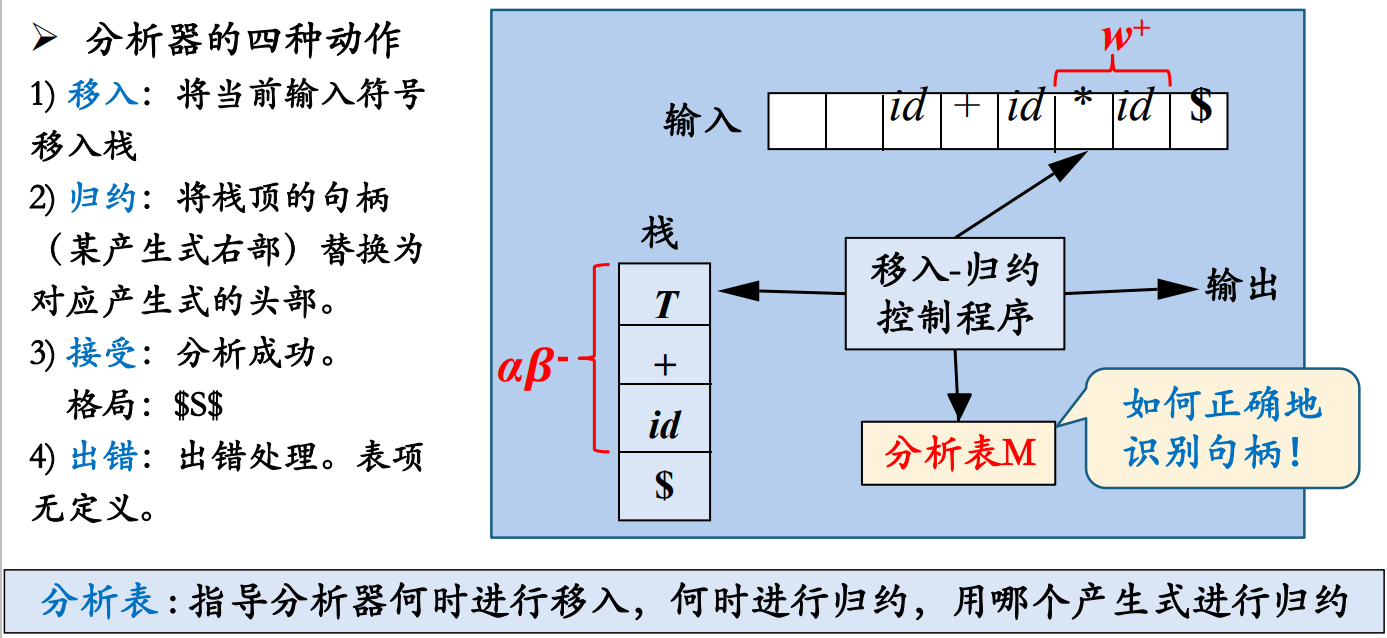
自底向上分析
从分析树的底部(叶节点)向顶部(根节点)方向构造分析树,可以看成是将输入串
移入 - 规约分析
通用框架是移入 - 规约分析:
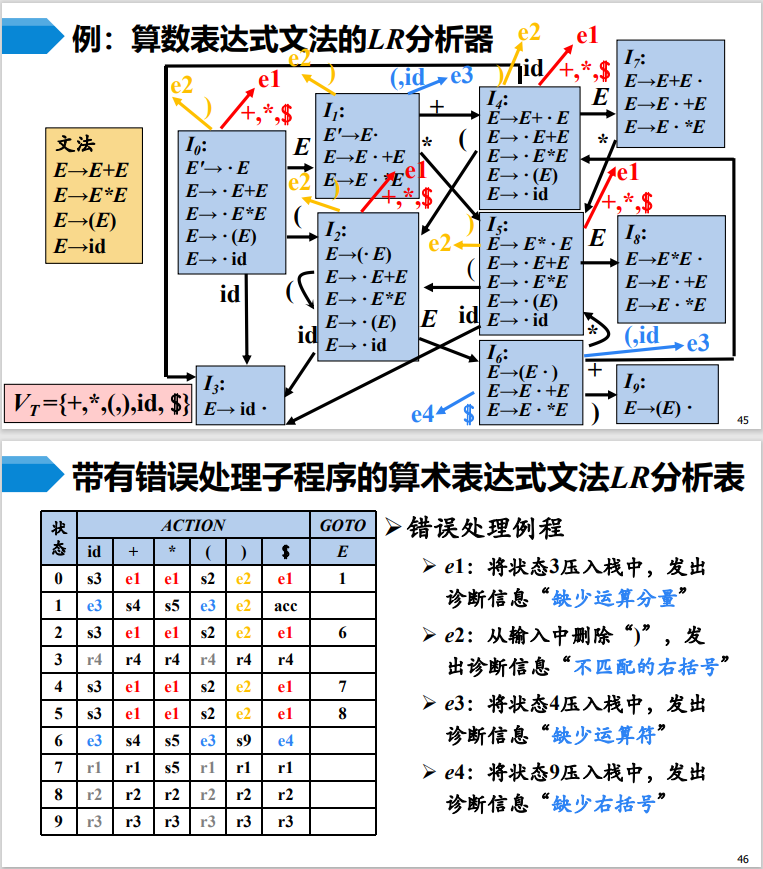
LR 分析法概述
与

工作过程
给定分析表,进行规约的过程如下:



那么如何求分析表呢?
增广文法
如果
:::note
引入这个新的开始产生式的目的是使得文法开始符号仅出现在一个产生式的左边,从而使得分析器只有一个接受状态
:::
项目集
自底向上分析的关键问题就是如何正确识别句柄。句柄是逐步形成的,我们用“项目”表示句柄识别的进展程度,右部某位置标有圆点的产生式称为相应文法的一个

定义后继项目:同属于一个产生式的项目,但圆点的位置只相差一个符号,如
可以把等价的项目组成一个项目集
举例如下:

构造算法
项目集
算法:

GOTO 函数:返回项目集
算法:

构造状态集:


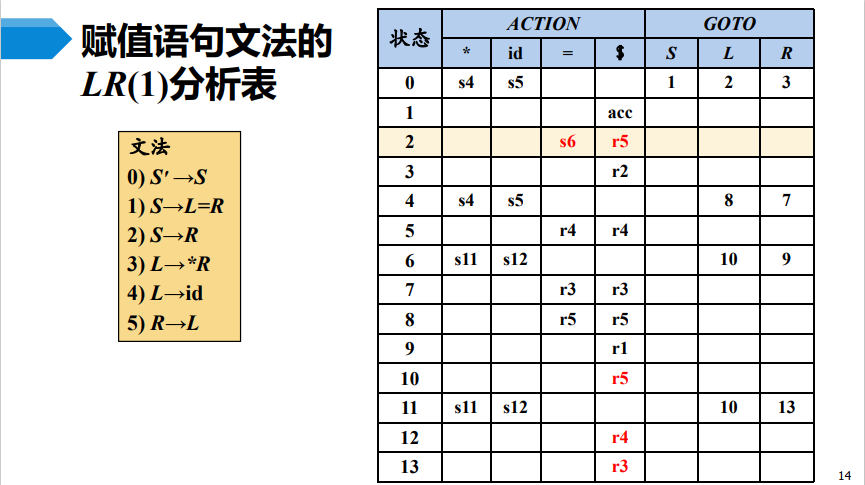
如图红色部分,当输入为 * 时,既可以移入也可以规约,这便是
SLR 分析
设有
如果集合
则可以根据下一个输入符号决定动作,即
- 若
,则移进 - 若
,则用 归约 - 此外,报错
举例:

SLR 分析中的冲突
如果

这便是 SLR 分析的局限性
SLR 只是简单地考察下一个输入符号
事实上,在特定位置,
规范
将形式为
继承与等价的定义:
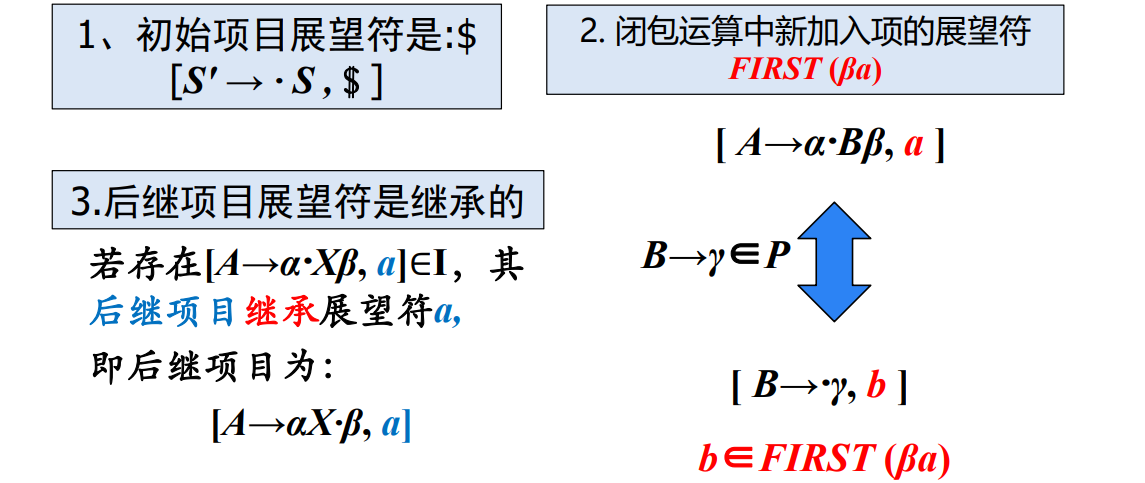
举例

缺陷
缺陷在于有很多状态是同心的,导致状态太多,并不实用。还可以进一步优化,即 LALR 分析法。
LALR 分析
方法是寻找具有相同核心的
LR 分析中的错误处理
当 LR 分析器在查询语法分析动作表并发现一个报错条目时,就检测到了一个语法错误
恐慌模式

- 从栈顶向下扫描,直到发现某个状态
,它有一个对应于某个非终结符 的 目标,可以认为从这个 推导出的串中包含错误 - 丢弃 0 个或多个输入符号,直到发现一个可能合法地跟在
之后的符号 为止 - 将
= 压入栈中,继续进行正常的语法分析
短语层次
检查 LR 分析表中的每一个报错条目,并根据语言的使用方法来决定程序员所犯的何种错误最有可能引起这个语法错误,举例: