本文介绍 Google DeepMind 团队在 2024 年 4 月 2 号发布的论文,地址:http://arxiv.org/abs/2404.02258
背景
在生活中,并不是所有的问题都需要相同的精力去解决。同样的,语言模型也并不需要对每个 token 都花费相同的计算量进行前向计算。比如,预测句中某个词很难,但是预测句末的句号很容易,而现阶段的模型在预测这两个 token 时会分配同样的计算资源,后者显然浪费了。我们能否让 Transformer 省去这些不必要的计算呢?
针对这个问题,论文作者使用类似 MoE 的方法,在整个网络深度上做动态 token 级别的路由决策,决定对哪些 token 进行 multi-head attention 和 MLP 的计算,哪些 token 保持不变以节省计算资源。论文将该策略称为深度混合(Mixture-of-Depths, MoD)。
方案
MoD 考虑在每一层的 multi-head attention 和 MLP (下称一个 block)前为输入的每一个 token 设置一个 路由器(得到一个标量权重),来确定该 token 是否需要这层的计算。
模型结构
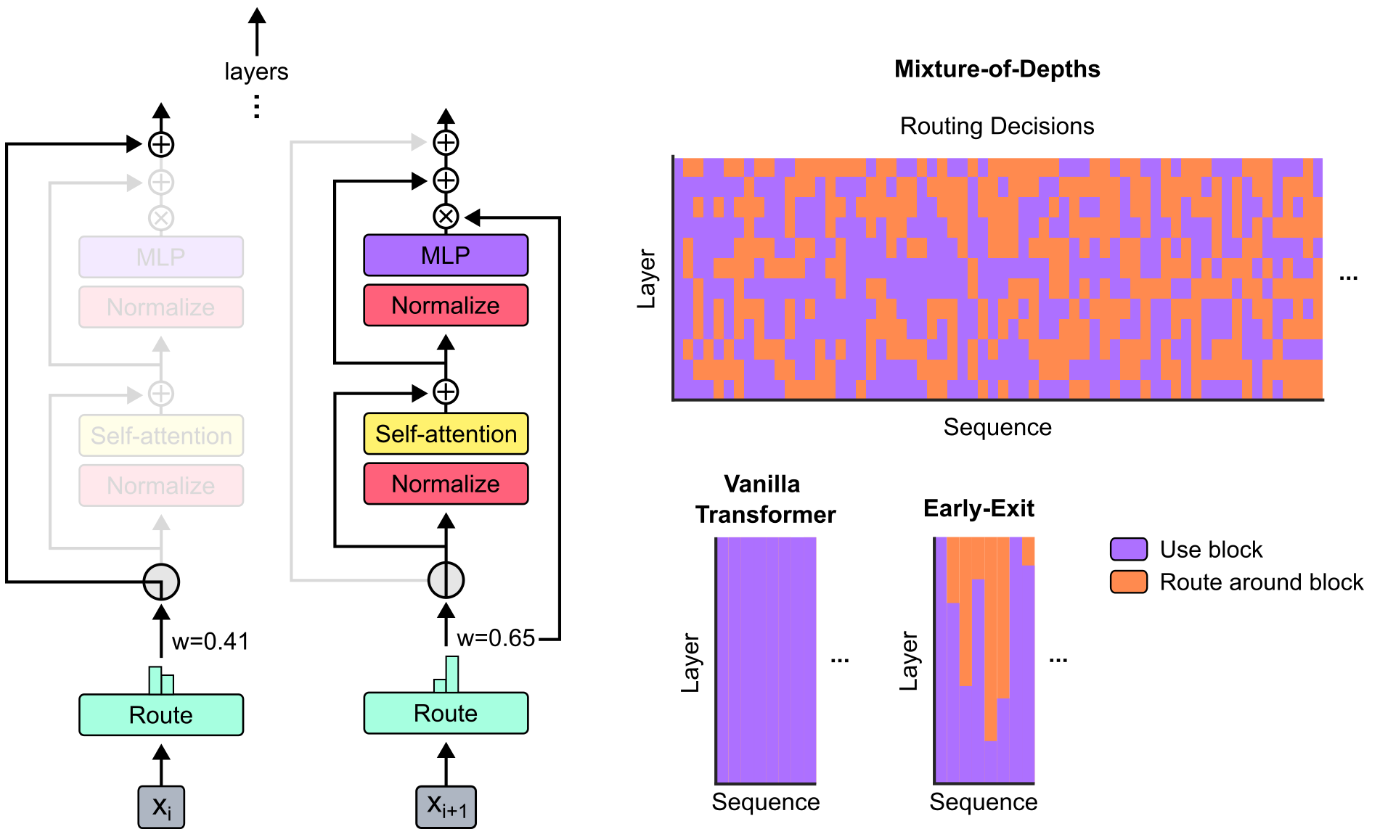
如上图所示,第
路由策略
原论文中讲述了两种路由的策略:
- token-choice,为每个 token 的每个可能的前向路径生成概率分布,并选择最大的概率路径
- expert-choice,为每条路径选择概率 top-k 的 token
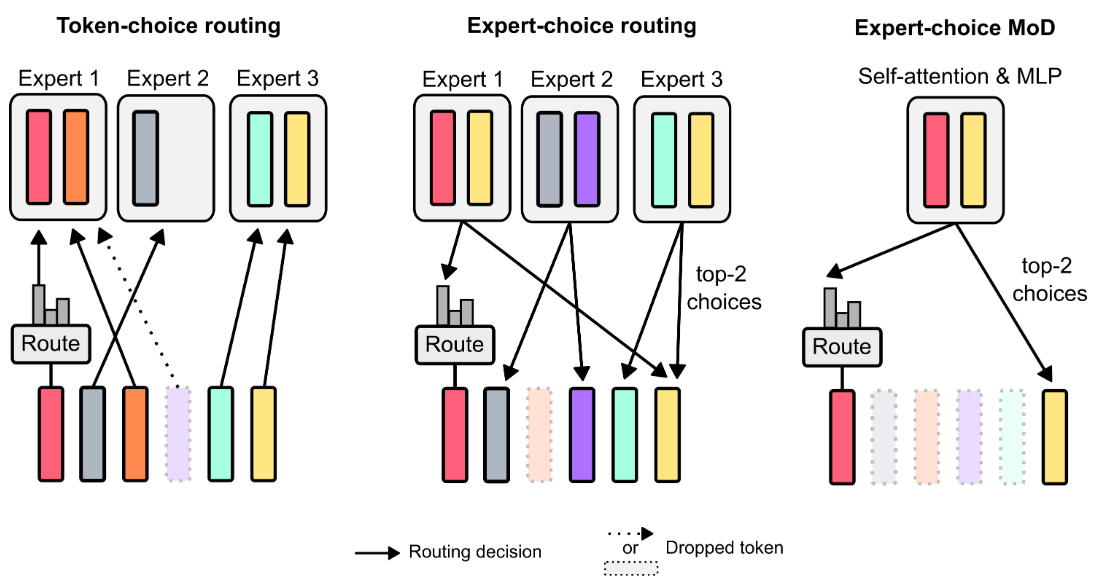
论文最后选择了 expert-choice,原因是论文提出的模型只有两条路径(即是否经过 block),取 top-k 可以直接将所有 token 分为两个互斥的集合,将 top-k 的 token 经过前向计算,其它 token 保持不变。
实验结果
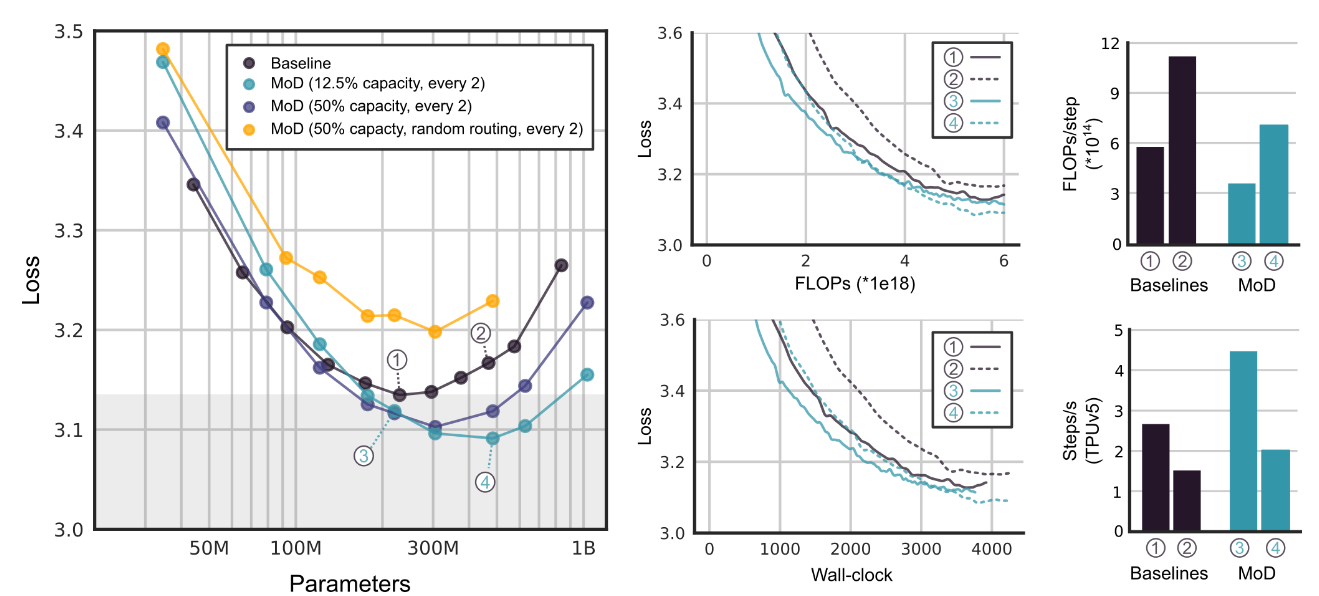
速度大幅提升! 下图表明,MoD 在保持相同性能的同时,速度比 isoFLOP 的基线模型快 66%
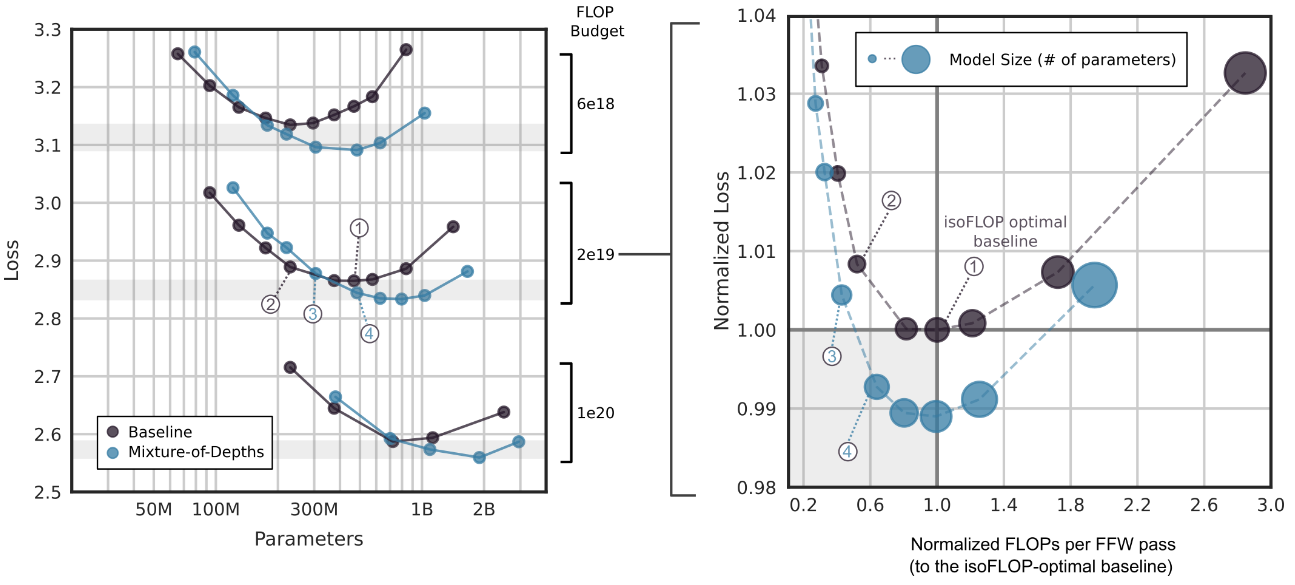
更快且更好! 下图是使用用 MoD 对 6e18、2e19 和 1e20 FLOP 执行 isoFLOP 分析的结果,发现比基线模型更快且性能更好
实现细节
目前官方代码还未开源,我实现了一份供参考:
class MoD(nn.Module):
def __init__(self, config, block):
super().__init__()
self.block = block
self.mod_router = nn.Linear(config.d_model, 1, bias=False)
self.capacity_factor = config.capacity_factor
self.top_k = int(config.capacity_factor * config.max_seq_len)
def forward(self, x):
bz, seq_len, d = x.shape
top_k = min(self.top_k, int(self.capacity_factor * seq_len))
# 计算每个token路由概率
router_logits = self.mod_router(x)
weights, selected_tokens = torch.topk(router_logits, top_k, dim=1, sorted=False)
selected_tokens, index = torch.sort(selected_tokens, dim=1)
weights = torch.gather(weights, dim=1, index=index)
indices_expanded = selected_tokens.expand(-1, -1, d)
top_k_tokens = torch.gather(x, 1, indices_expanded)
# 对top_k的token前向计算
top_k_tokens_processed = self.block(top_k_tokens)
# 其它token保持不变
x = torch.scatter_add(
x,
dim=1,
index=indices_expanded,
# 结果需乘路由权重,见论文
src=top_k_tokens_processed * weights
)
return x