深度学习模型的优化算法
本文讲解训练深度学习模型的优化方法,包括优化器与初始化参数的策略。
问题的引入
一个有偏置项的全连接网络可以通过如下方式定义:
其中,
当一个 batch 有多个样本时,则可写成矩阵的形式如下:
注意,
为了去训练一个全连接网络或者任何深度学习模型,我们不得不思考如下几个问题:
- 如何选择网络的宽度与深度?
- 如何优化目标函数?
- 如何初始化网络的权重?
- 如何保证网络在多次优化迭代后仍能继续训练?
优化算法
这里仅讨论梯度算法,先考虑以下两类:
- 批量梯度下降法。这是根据所有训练集估计梯度的算法,得到的是标准梯度,一定能保证收敛到极值点。但是缺陷在于计算太慢,且非常容易爆显存,一般只在高精度的任务中用到。
- 随机梯度下降法。与第一条相反,这种方法每次只随机选取单个样本估计梯度。这种算法的缺陷很明显,梯度估计很不准确,会让参数在极值点附近剧烈抖动,并且无法并行计算。
综合以上算法,使用一个以上而又不是全部的训练样本就有了深度学习中最常用的小批量(minibatch)随机梯度下降法,现在,通常也将其叫作随机梯度下降法,后文皆用该名称指代。
随机梯度下降法
提到优化算法,首先想到的就是随机梯度下降法(SGD)。每次抽取

优点:
- 既有较为精确的梯度估计,又能保证适宜的计算效率
缺点:
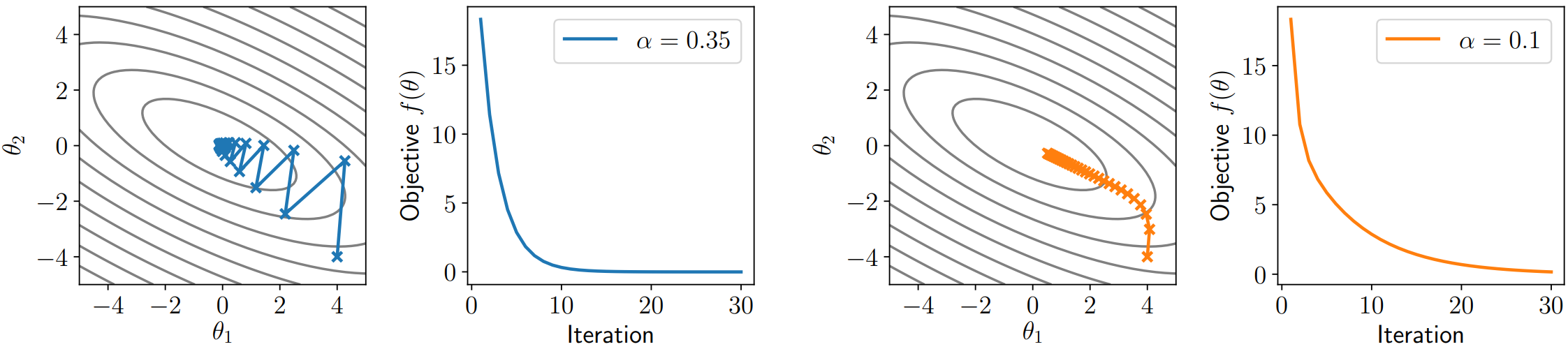
- 学习率难以确定,设置过小会使收敛速度太慢,设置过大会使其剧烈震荡甚至不收敛。
比如,对于
牛顿法
考虑上面随机梯度下降算法的缺点,一个重要的方面就是震荡问题,如何减轻震荡呢?牛顿法就是这样一种更全局的方法,它在选择下一步的更新方向时,不仅仅考虑一阶导数最大的方向,还会考虑二阶导数,即走完这一步后,导数会不会变得更大。
参数更新步骤如下:
其中,
牛顿法默认
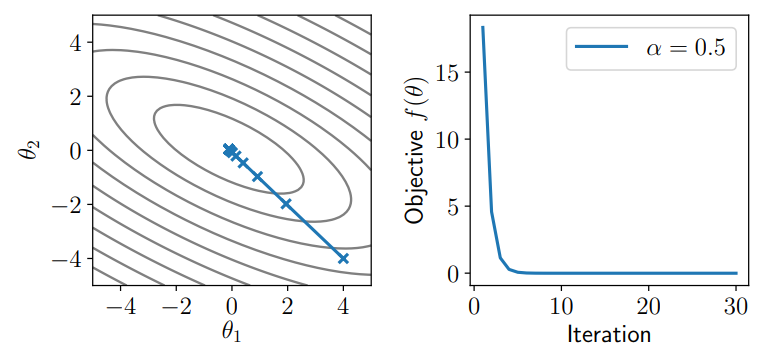
优点:
- 可以看到,牛顿法在更新时没走“弯路”,每次都指向极值点的位置,解决了震荡的问题
缺点:
- Hessian 矩阵的计算消耗太大,在深度学习问题中是不切实际的
- 牛顿法仅适用于凸优化问题,对于非凸函数的优化,Hessian 甚至都不是正定的
动量法
受以上两种方法的启发,考虑在梯度下降法中结合一些像牛顿法一样的全局结构,这就是动量法的思想。动量法引入动量项
从物理角度上来理解,可以将该算法视为牛顿力学下的粒子运动,当前的负梯度为粒子受到的力,目标函数的值为粒子的位置。那么每一步的负梯度也就是粒子受到的力会改变粒子的动量,当力的方向改变时,则根据矢量加法得到粒子下一步的动量方向,这也解释了该算法求历史负梯度平均的意义。
下图就是普通随机梯度下降法(
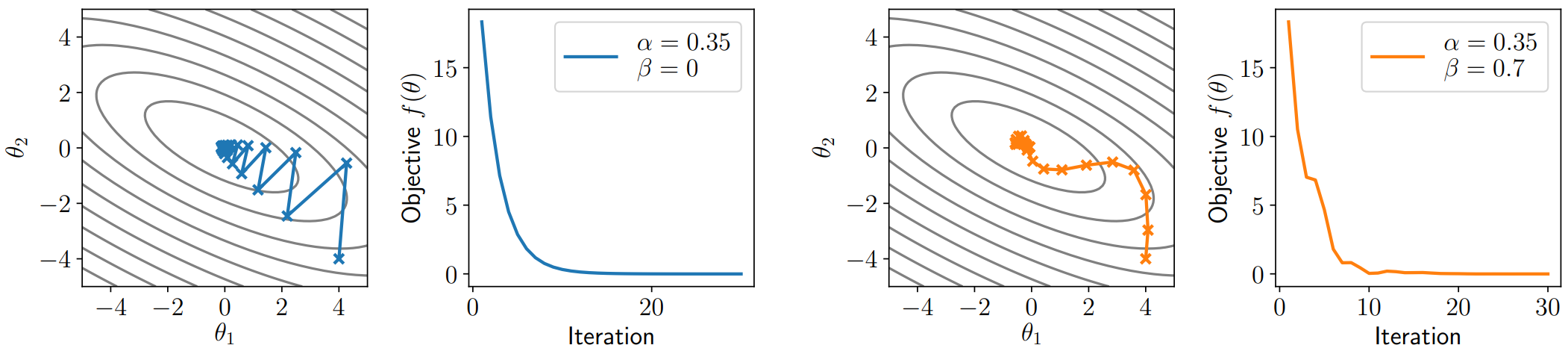
动量在计算初期很小,参数更新会很慢,通常在更新时给其乘以一个按时间衰减的系数:
Nesterov 动量法
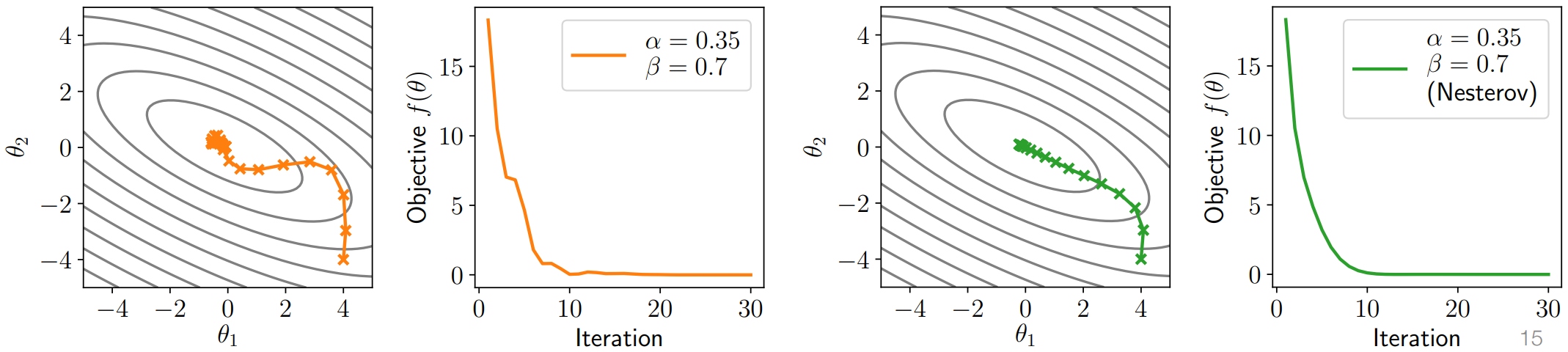
这是动量法的一个改进。它的改变在于动量的更新:它根据超前一步的梯度来更新动量,更新步骤如下:
事实上,也可以写成下面的形式:
这种改进本质上是考虑了目标函数的二阶导信息,所以有了更快的收敛速度。这里不详细推导,可以参考下面这篇知乎文章:
比Momentum更快:揭开Nesterov Accelerated Gradient的真面目 - 知乎 (zhihu.com)
如图是二者的对比:
Adam 算法
为了解决学习率的设置问题,近年来提出了一些自适应学习率算法,本文只介绍 Adam 算法。这个算法也可以看作结合了动量的算法,更新步骤如下:
事件中,通常还要做无偏修正:
效果如图所示,非常惊艳!
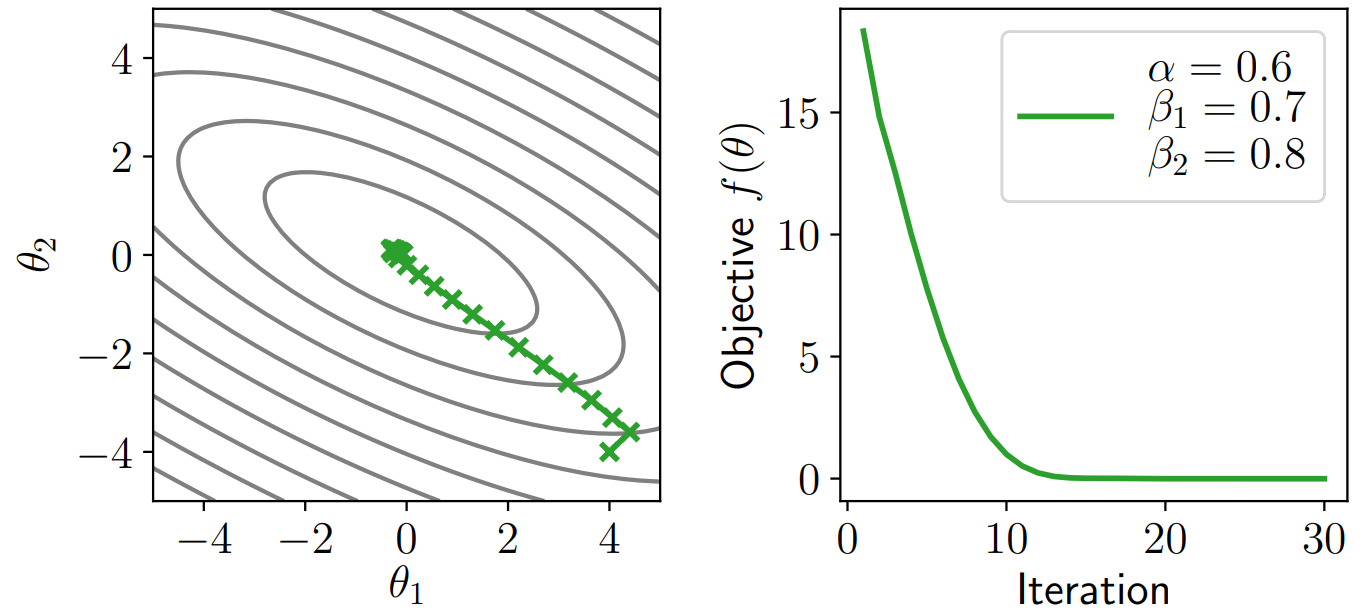
初始化算法
模型参数的初始化对深度学习模型训练的影响非常大。比如,回顾我们前面的 MLP,假设将
设
Xavier 初始化
这种初始化算法适合激活函数为 sigmoid 或 tanh 的情况。
均匀分布:
高斯分布:
这里不做推导,可见论文 Understanding the difficulty of training deep feedforward neural networks
Kaiming 初始化
Kaiming 初始化是针对 Xavier 初始化在 ReLU 这一类整流线性激活函数表现不佳而提出的改进。
均匀分布:
高斯分布:
对于 ReLU 函数,
下面对高斯分布的正向过程做一些理论说明:
考虑使用高斯分布初始化参数,即
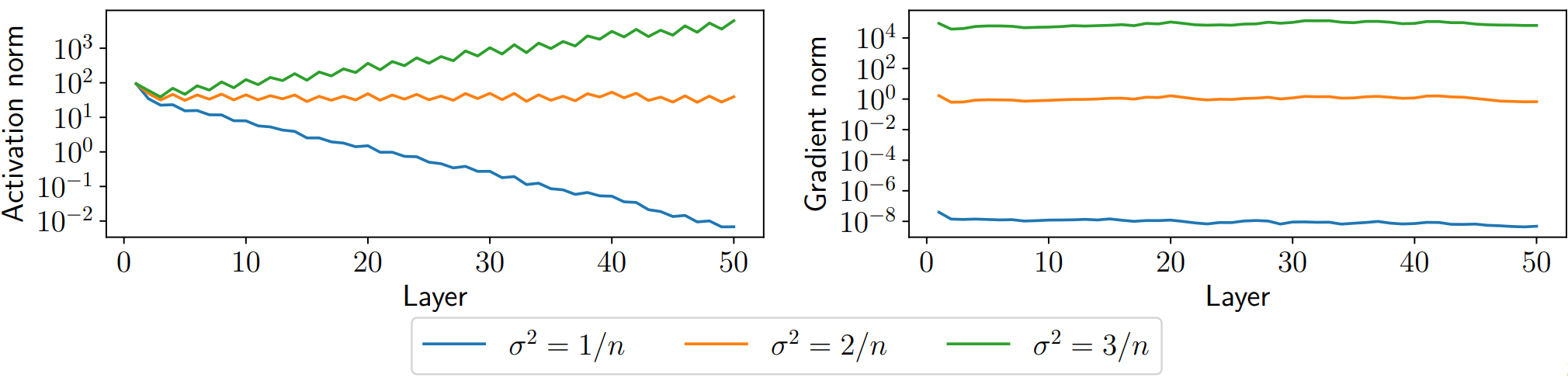
通过上图,我们发现方差的选择对训练有巨大的影响,在
考虑将网络的中间层变量视为符合高斯分布的相互独立的随机变量,
所以,如果我们使用线性激活函数,
回到上面的例子,如果使用 ReLU 激活函数,有一半的
这个结果与前面给出的公式
参考资料
- https://www.deeplearningbook.org/contents/optimization.html
- https://dlsyscourse.org/slides/fc_init_opt.pdf
- https://zhuanlan.zhihu.com/p/570846395
- https://zhuanlan.zhihu.com/p/22810533
- http://txshi-mt.com/2018/11/17/NMT-Tutorial-3c-Neural-Networks-Initialization/
- Understanding the difficulty of training deep feedforward neural networks
- Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification