壹 - 实现计算图与自动求导
在前一篇文章中,我们搭建过一个简单的两层神经网络:
在这个神经网络中,我们通过手动计算梯度再用随机梯度下降法实现了对两个权重矩阵的更新。但是一旦层数变多,模型变得更加复杂,手动计算就非常烦琐了。本文将搭建深度学习框架中最重要的结构——计算图,并由此实现自动求导机制。
计算图原理
计算图就是一个表示运算的有向无环图。图中的每个节点都表示一个变量和一种运算(叶子节点只表示变量)。比如下面这个计算:
可以构造计算图:
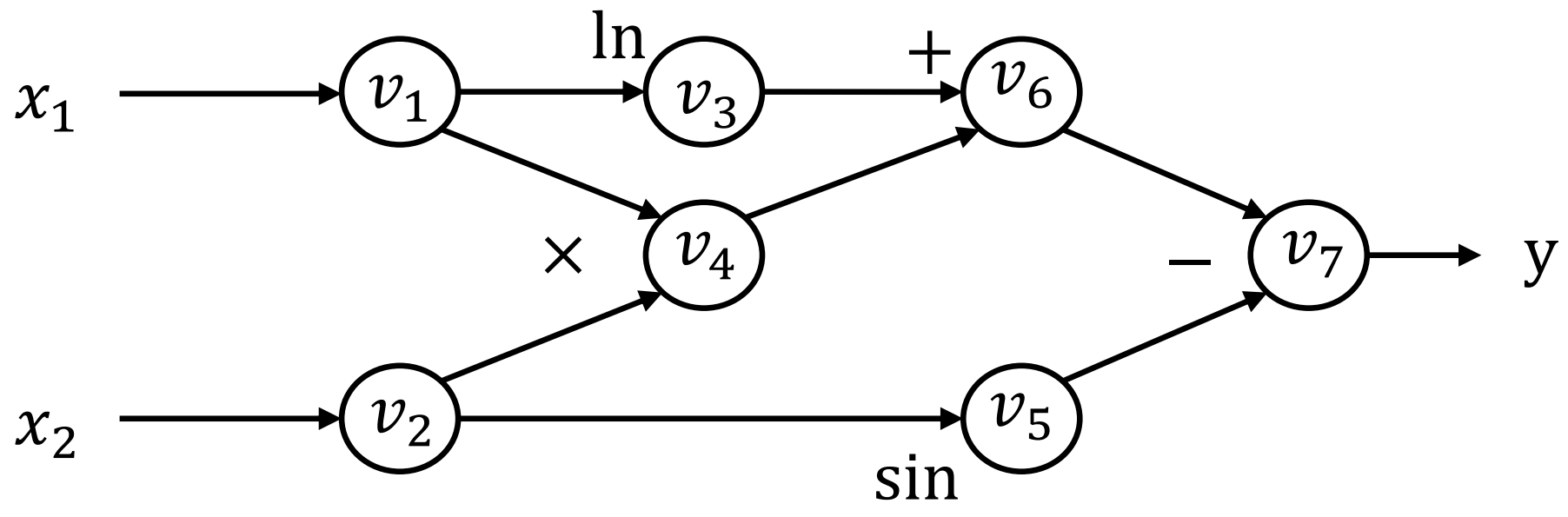
正向计算求值的过程我们称为正向传播
那么如何求得结果
正向模式
一种很自然的想法是从图中的叶子节点开始,按拓扑排序的顺序计算每个中间节点对原始输入的倒数,记
这种做法看起来很简单,但是它有一个缺陷在于,对于函数
反向模式
顾名思义,这种做法就是从输出节点逆着求导,记
注意一个节点被多个节点作为输入节点的情况:
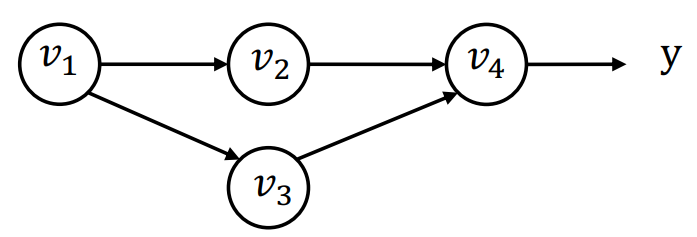
当计算得到
因此,我们可以定义局部伴随值,对于每个把
自动求导
到此,我们就能给出反向模式的自动求导算法:

在具体实现时,对于每一个节点的伴随值和局部伴随值我们也作为一个计算图节点来表达。举如下计算图的例子:
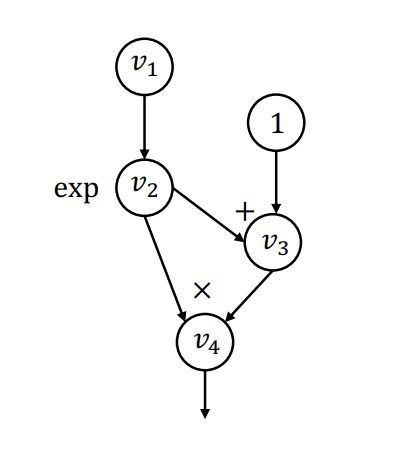
则算法流程如下:
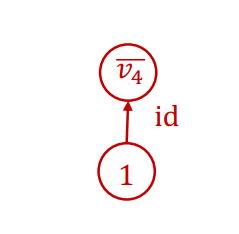
- 初始化
的伴随值为 1。因此,第一步计算得到
- 对于
的输入 ,计算 ,这一步计算也能用计算图来表示。将这一步计算得到局部的伴随值加入词典中,对于 ,它只有一个输出,所以可以直接计算得到
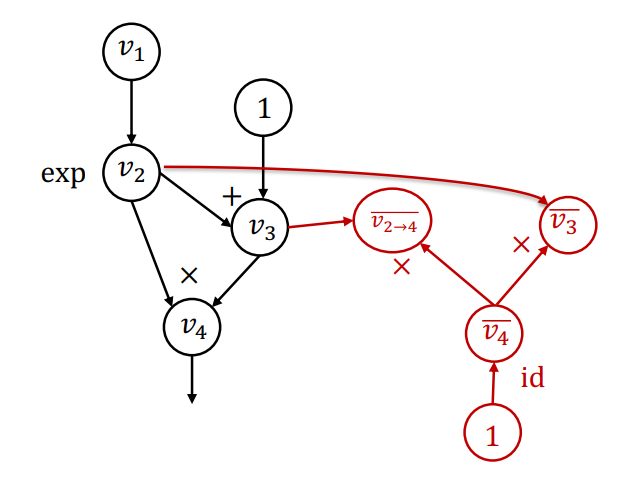
- 最终,算法得到的扩展计算图为
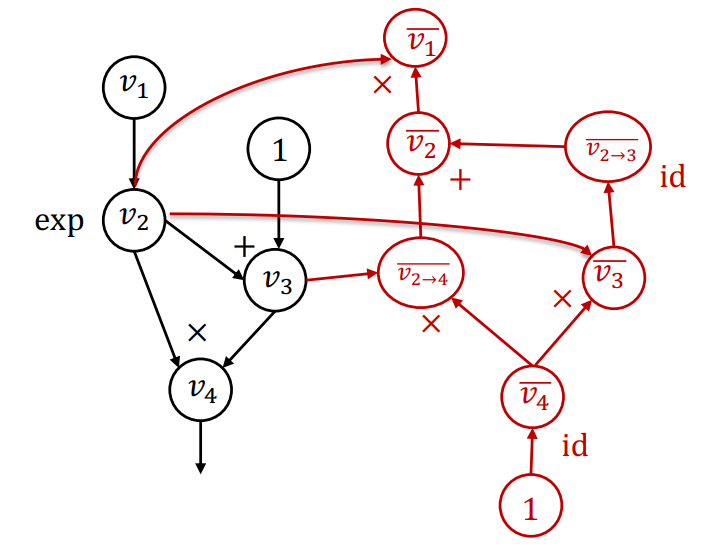
这种反向模式的算法与通常意义上的反向传播似乎并不相同,为什么要这样扩展计算图来计算,而不是直接将梯度计算并保存到每个原始的计算图节点中呢?
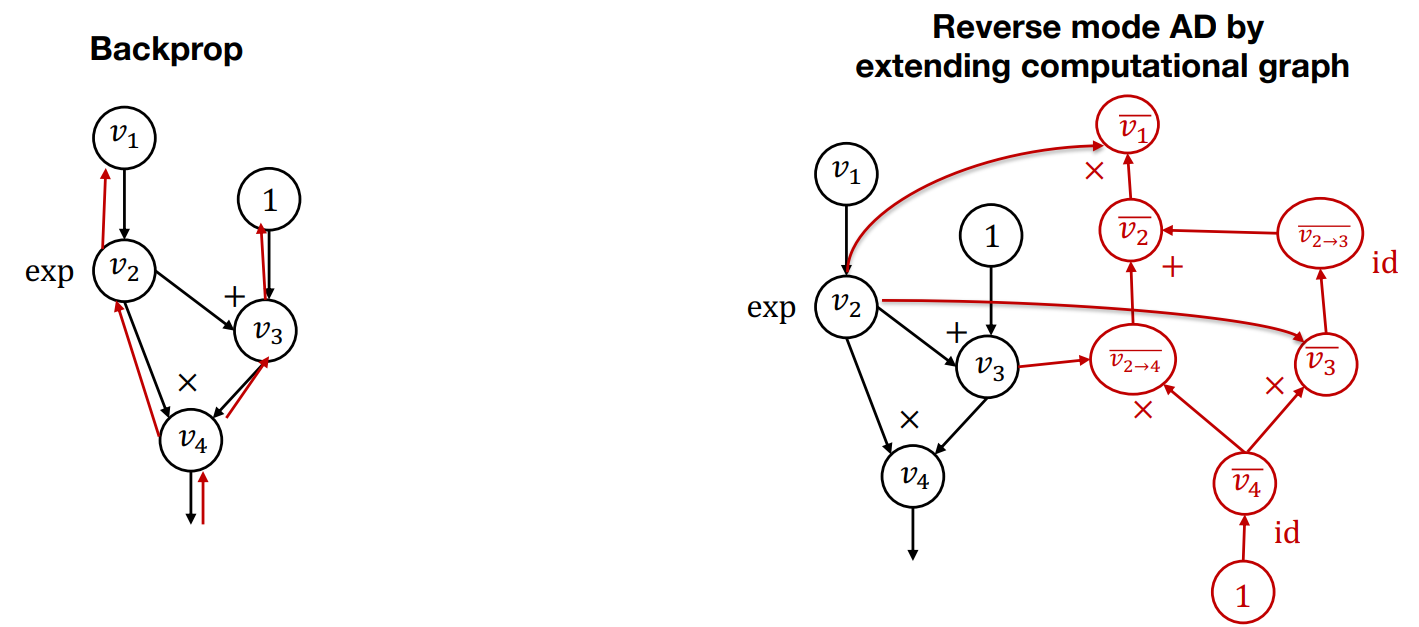
- 在反向传播中,我们的伴随值都丢失了,无法计算梯度的梯度
- 在反向模式中,我们可以进一步扩展计算图得到我们想要的结果,并且在计算过程中可以做进一步的优化
因此,第一代的框架(caffe, cuda-convnet)等都用的是反向传播,而现代的框架(PyTorch, TensorFlow)等都是用反向模式进行自动求导。
Jacobian 矩阵
我们上述的做法都是基于标量的,如何扩展到多维向量呢?可以用 Jacobian 矩阵解决这个问题:
设
代码实现
接下来就开始实现计算图以及反向模式自动求导吧!这部分内容也对应于 CMUDeep Learning Systems 课程的作业 1
计算图节点抽象
由前文说到的,每一个计算图节点都要保存一个变量和一个运算,定义我们的计算图节点 Value 类:
class Value:
"""A value in the computational graph."""
# trace of computational graph
op: Optional[Op]
inputs: List["Value"]
# The following fields are cached fields for
# dynamic computation
cached_data: NDArray
requires_grad: bool
def realize_cached_data(self): # 得到节点对应的变量
def is_leaf(self): # 是否为叶节点
def __del__(self):
def _init(self,op: Optional[Op],inputs: List["Tensor"],*,num_outputs: int = 1,cached_data: List[object] = None,requires_grad: Optional[bool] = None):
@classmethod
def make_const(cls, data, *, requires_grad=False): # 建立一个用data生成的独立的节点
def make_from_op(cls, op: Op, inputs: List["Value"]):# 根据op生成节点
op:表示这个节点的运算操作inputs:是一个列表,保存所有前向计算图节点cached_data:实际上就是保存这个节点的变量require_grad:该节点是否需要进行梯度计算
函数 realize_cached_data 的具体实现:
def realize_cached_data(self):
"""Run compute to realize the cached data"""
# avoid recomputation
if self.cached_data is not None:
return self.cached_data
# note: data implicitly calls realized cached data
self.cached_data = self.op.compute(
*[x.realize_cached_data() for x in self.inputs]
)
self.cached_data
return self.cached_data
- 这个函数是最关键的函数,它通过委托
op类下的compute函数对输入节点进行计算求值
运算操作抽象
op 类主要就是定义两个操作:
- 正向计算
- 反向求导
class Op:
"""Operator definition."""
def compute(self, *args: Tuple[NDArray]):
"""Calculate forward pass of operator.
Parameters
----------
input: np.ndarray
A list of input arrays to the function
Returns
-------
output: nd.array
Array output of the operation
"""
def gradient(
self, out_grad: "Value", node: "Value"
) -> Union["Value", Tuple["Value"]]:
"""Compute partial adjoint for each input value for a given output adjoint.
Parameters
----------
out_grad: Value
The adjoint wrt to the output value.
node: Value
The value node of forward evaluation.
Returns
-------
input_grads: Value or Tuple[Value]
A list containing partial gradient adjoints to be propagated to
each of the input node.
"""
def gradient_as_tuple(self, out_grad: "Value", node: "Value") -> Tuple["Value"]:
""" Convenience method to always return a tuple from gradient call"""
Tensor 类的实现
前面提到,每一个 Tensor 都是一个计算图节点,因此,其是 Value 类的一个子类。
class Tensor(Value):
grad: "Tensor"
def __init__(self,array,*,device: Optional[Device] = None,dtype=None,requires_grad=True,**kwargs):
@staticmethod
def _array_from_numpy(numpy_array, device, dtype):
@staticmethod
def make_from_op(op: Op, inputs: List["Value"]):
@staticmethod
def make_const(data, requires_grad=False):
@property
def data(self):
@data.setter
def data(self, value):
def detach(self):
@property
def shape(self):
@property
def dtype(self):
@property
def device(self):
def backward(self, out_grad=None):
...重载运算符...
注意 detach 函数:
def detach(self):
"""Create a new tensor that shares the data but detaches from the graph."""
return Tensor.make_const(self.realize_cached_data())
def make_const(data, requires_grad=False):
tensor = Tensor.__new__(Tensor)
tensor._init(
None,
[], # 将前置节点置空
cached_data=data
if not isinstance(data, Tensor)
else data.realize_cached_data(),
requires_grad=requires_grad,
)
return tensor
- 这个函数很有用,它能把节点从计算图剥离出来,防止无效地增加计算图规模(比如梯度下降法更新权重矩阵时)
make_from_op 函数:
def make_from_op(op: Op, inputs: List["Value"]):
tensor = Tensor.__new__(Tensor)
tensor._init(op, inputs)
if not LAZY_MODE:
tensor.realize_cached_data()
return tensor
- 它通过运算操作,和两个输入节点,生成一个新的节点,这个节点的
inputs就是这两个输入节点,从而将其加入计算图中 LAZY_MODE的作用可以定义在图建好后再计算
运算操作类实现
对于 Tensor 之间的运算,每次运算都应创建一个新的计算图节点并将它加入计算图中,因此定义 TersorOp 作为 Op 的一个子类:
class TensorOp(Op):
""" Op class specialized to output tensors, will be alternate subclasses for other structures """
def __call__(self, *args):
return Tensor.make_from_op(self, args)
它重写了 __call__ 函数,这个函数委托 Tensor 中的 make_from_op 函数创建一个新的计算图节点 Tensor,通过它就能追踪 Tensor 之间的运算。
接下来对于每一种运算,它都要继承自 Tensor 我们都要重写 compute 函数和 gradient 函数
class EWiseAdd(TensorOp): # 加
class AddScalar(TensorOp): # 加常数
class EWiseMul(TensorOp): # 对应元素乘
class MulScalar(TensorOp): # 乘常数
class PowerScalar(TensorOp):# 常数幂
class EWiseDiv(TensorOp): # 对应元素除
class DivScalar(TensorOp): # 除以常数
class Transpose(TensorOp): # 颠倒维度
class Reshape(TensorOp): # 变形
class BroadcastTo(TensorOp):# 广播
class Summation(TensorOp): # 维度求和
class MatMul(TensorOp): # 点乘
class Negate(TensorOp): # 求相反数
class Log(TensorOp):
class Exp(TensorOp):
本文中实现上述操作所需要的矩阵运算我们都使用 numpy 来进行,通过 import numpy as array_api,后续我们将自己实现这些运算,到时候只需要将 numpy 换为自己的 api 即可
计算图 de 建立
考虑如下操作会发生什么:
x = ndl.Tensor([1, 2, 3], dtype="float32")
y = x + 1
当运行 y+1 时,会调用 Tensor 中重载的 __add__ 函数:
def __add__(self, other):
if isinstance(other, Tensor):
return needle.ops.EWiseAdd()(self, other)
else:
return needle.ops.AddScalar(other)(self)
-
它判断相加的是常数还是另一个张量,并委托调用相应的
TensorOp的子类的构造函数,也就是我们前面实现的具体操作类。 -
而前面提到的
TensorOp有一个__call__函数,此时它会调用make_from_op,把当前运算操作类和inputs传进去,生成新的计算图节点
由此我们就实现了张量运算的跟踪
自动求导实现
当调用 Tensor 中的 backward 函数时,我们就期望得到每个节点的梯度:
def backward(self, out_grad=None):
# 最后一个节点时,out_grad为1
out_grad = out_grad if out_grad else Tensor(numpy.ones(self.shape))
compute_gradient_of_variables(self, out_grad)
实现我们之前讲解的反向模式算法即可:
def compute_gradient_of_variables(output_tensor, out_grad):
"""Take gradient of output node with respect to each node in node_list.
Store the computed result in the grad field of each Variable.
"""
# a map from node to a list of gradient contributions from each output node
node_to_output_grads_list: Dict[Tensor, List[Tensor]] = {}
# Special note on initializing gradient of
# We are really taking a derivative of the scalar reduce_sum(output_node)
# instead of the vector output_node. But this is the common case for loss function.
node_to_output_grads_list[output_tensor] = [out_grad]
# Traverse graph in reverse topological order given the output_node that we are taking gradient wrt.
reverse_topo_order = list(reversed(find_topo_sort([output_tensor])))
for node in reverse_topo_order:
node.grad = sum(node_to_output_grads_list[node])
if node.is_leaf():
continue
for i, grad in enumerate(node.op.gradient_as_tuple(node.grad, node)):
j = node.inputs[i]
if j not in node_to_output_grads_list:
node_to_output_grads_list[j] = []
node_to_output_grads_list[j].append(grad)
gradient_as_tuple函数调用相应运算操作类重写的gradient函数计算输入节点的梯度
完整代码
见我的 Github 仓库:
Deconx/CMU-DL-Systems: CMU 10-714 Deep Learning Systems 2022 秋季学期课程作业实现 (github.com)