Note1- 信息检索模型
信息检索模型是一个四元组
- :文档集的机内表示
- :用户需求的机内表示
- :文档表示、查询表示和它们之间的关系的模型框架
- :排序函数,给 和 评分
布尔模型
布尔模型是一种最简单的信息检索模型,它返回所有满足布尔表达式的文档。
比如,有如下查询:
Which plays of Shakespeare contain the words Brutus and Caesar, but not Calpurnia?
那么对应的查询就是:Brutus AND Caesar AND NOT Calpurnia
关联矩阵
于是可以定义词项与文档的关联矩阵,对于每一个词项,如果其在对应的文档出现过,就将该位置设置为 1,如:

那么当我们要求 Brutus AND Caesar AND NOT Calpurnia 时,只需要对 Calpuria 所在的行求反,然后将这三个向量按位“与”,最后得到的向量就标识了哪些文档符合这个条件。
向量空间模型
同样是用一组向量来表示文档 , 指出现在文档中能够代表文档性质的基本语言单位,即检索词。
词袋模型
即不考虑文档中词的顺序的模型。
设 表示词项 在文档 中出现的次数,那么就可以定义文档和查询之间的匹配程度为:
考虑高频词含有的信息量往往比低频词要少。因此,设 为词项 在文档集合中出现的文档数目,那么就可以定义**倒置文档频率 (IDF)**为:
IDF 衡量了一个词的信息量大小。
那么就可以把文档 中的一个词项 的权值定义为:
即:
- 一个词对于一个文档的重要性随着它在该文档中出现次数的增加而增加
- 随着它出现的所有文档的数量的增加而减少
相似度衡量
- 内积
- 余弦相似度
- Jaccard 系数
概率模型
假设相关度 是二值的,即 表示文档 与查询 是相关的,我们利用概率模型来估计每篇文档和查询之间的相关性概率,然后对结果进行降序排列:
二值独立模型
- :当返回一篇相关文档时,文档为 的概率
- :对于查询 ,返回一篇相关文档的先验概率,可以根据文档集合中相关文档所占的百分比估计
定义排序函数:
根据贝叶斯条件独立性假设,一个词的出现与否,与任意一个其他词出现与否互相独立,故
从而
令
- ,词项出现在一篇相关文档中的概率
- ,词项出现在一篇不相关文档中的概率
最后的排序函数为:
最终,就得到了我们的检索状态值
令
举例,假设有如下统计信息:
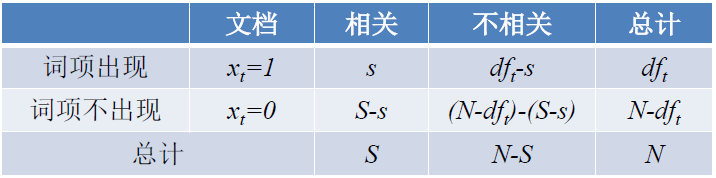
则
BM25 模型
- :文档 的长度
- :词项 在文档 中的权重
语言模型
文档集中的每篇文档 构建其对应的语言模型 ,我们的目标是将文档按照其与查询相关的似然 排序
- 对所有的文档都相同,可以忽略
- 是先验概率,可以视为均匀分布,也可以忽略
- 是在文档对应的语言模型下生成 的概率
这样估计 :
概率平滑
如果一个词在查询中出现了,但在文档中没有出现,那么 ,这很不合理。于是就需要概率平滑。
是基于全部文档集构造的语言模型。
这个语言模型公式的本质可以理解为:
- 用户心中已经有了一篇理想文档,根据这篇文档生成了查询
- 要返回用户心目中的文档的概率